
Give Your AI Tools a Makeover (from SKILLS 2023)
What is the problem?
Many law firms have been using AI tools to support their transactional practices for a number of years - for example, extracting clauses for due diligence, finding key data points when reviewing contracts, and identifying risks in underlying documents.
In order to provide law firms with the data they need, many of these AI tools offer the ability to train bespoke models. In our conversations, we have heard frustrations from firms that they want “better AI” and that they are tired of spending a lot of time to train bespoke models.
We want to help law firms make the best of the tools they have in place already. We found there are three key levers law firms can influence to improve the performance of bespoke models and enhance their experience working with these AI tools:
picking a different model or product
collecting more data for training
minimizing the noise in the trainnig data
It was not clear which of the three levers had the biggest impact on the performance of these AI tools.
In January 2023, we ran a set of experiments to test the impact of these levers, and correspondingly, infer how law firms may choose to spend their time.
Our SKILLS presentation
We were lucky enough to present the findings from our research at this year’s SKILLS event (https://skills.law/). In our session, we presented with Cathy Goodman on how every law firm can make better use of their existing AI tools (no matter what the tool is).
In our session:
we will give an overview of common machine learning technologies used to classify and extract text data
we will share examples of how to get more out of these different tools (e.g. by capturing, cleaning and preparing your data, scaling usage, running an effective team, and working with vendors)
we will also give a few tips on how to connect your data to KM principles and futureproof your work for the next wave of AI that makes use of neural networks
You can watch a recording of our session on the SKILLS website.
On this blog, we wanted to share additional information that we did not have time to cover in the video.
The data we are sharing helps answer questions like:
“should we keep finding more data to train the model?”
“what is the optimal number of data points to collect?”
“how much dirty data can our model tolerate?”
“how much do we have to spend reviewing the quality of the data?”
“will it help if we tried a different product?”
“how much time should we allocate to reviewing predictions made by the trained models?”
Performance at different data sizes
We found there are vast differences in performance of classification models at different data size.
Below are the four bar charts of F-1 scores of different models with different number of training points.




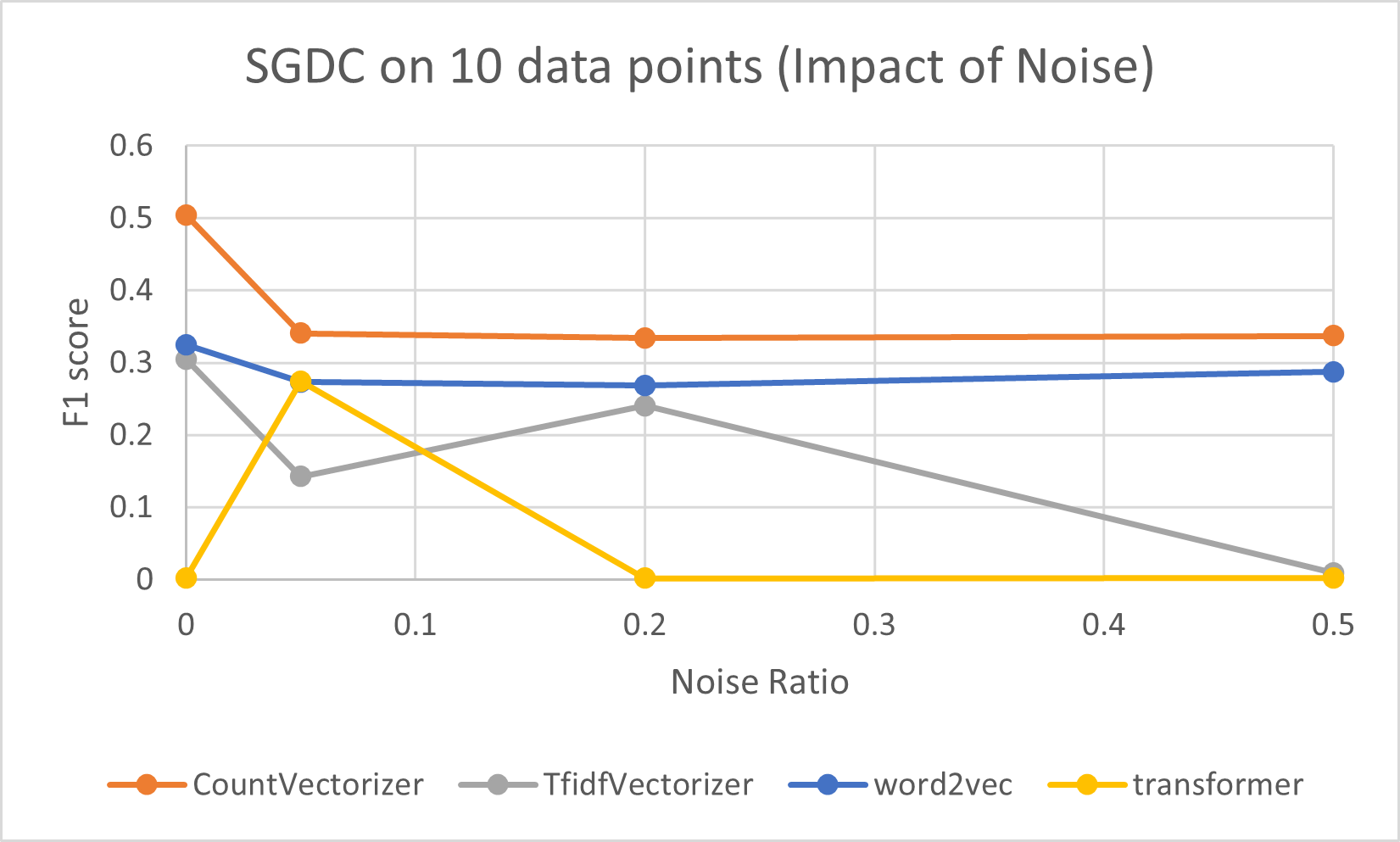
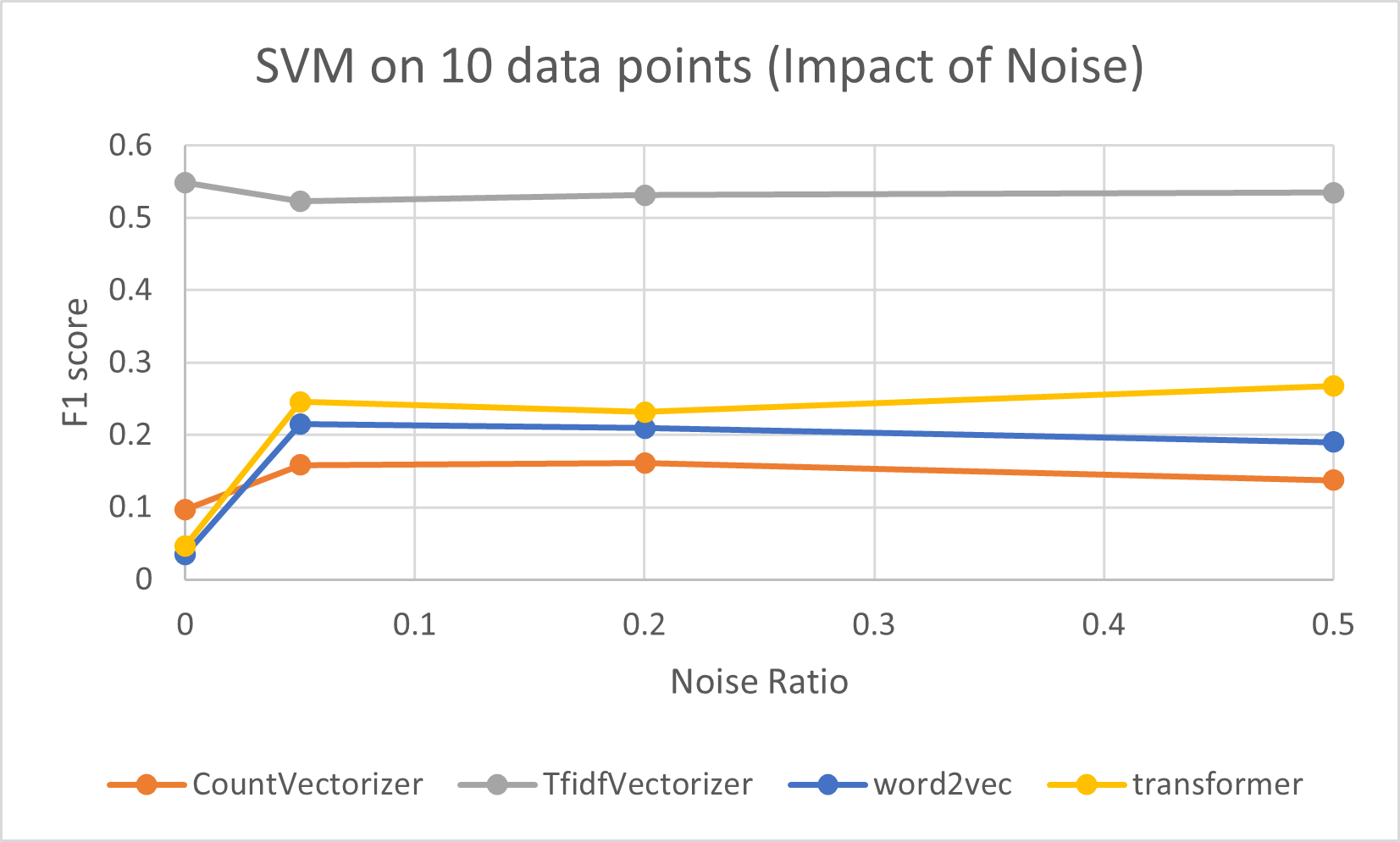
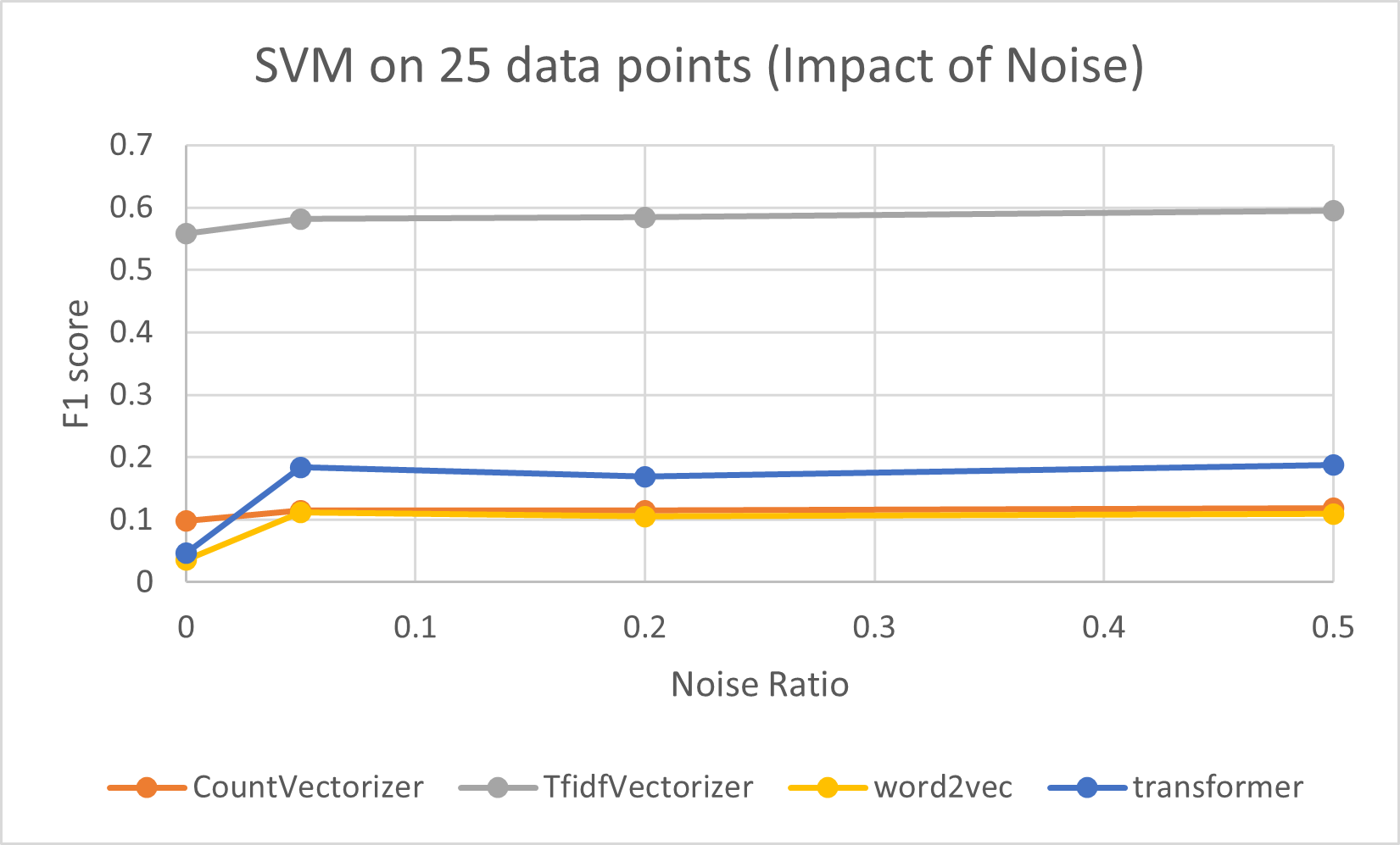
Impact of noise on different models
We found that noise in the data leads to significant degradation in the performance of classification models.
Below are 28 different charts showing the effect of noisy data using different models and different levels of training data.

























Additional resources
Our research covers only the base case of using these models, and this blog provides only a snippet of the highlights from our findings.
To find out more information:
Our research paper covers our findings and assumptions in more depth. If you want to read our research paper (in draft), please visit our Dropbox link here.
If you want to receive an Excel spreadsheet of the test results, please email us at hello [at] syntheia.io.